Deciphering the Clean Energy Twittersphere

Background:
Global warming has been an alarming phenomenon since the start of the industrial revolution in the 18th century. Current practices of fossil fuel dependence and environmental destruction are unsustainable for the planet and threaten the availability of future resources. Clean energy technology has gained some traction over the years, but not nearly enough to combat the large carbon footprint of fossil fuel. With so many complications happening in the world, it is difficult to keep track and understand the significance of each one. A more coherent form of communication can not only inform people of the most critical problems, but also promote conversations and action with lasting impact in communities.
Social media is one such tool that has enabled mass communication. In the past decade, it has been proven to have profound influence on human behavior and beliefs. Twitter is an example of a social media platform that allows celebrities and popular figureheads to easily reach a wider audience with their opinions and insights. With a large user database of over 300 million, Twitter has the power to spread information that are crucial to creating a safer and more sustainable world.
Data:
This project analyzes and interprets tweets of major influencers within the clean technology and environmental communities. These include politicians, journalists, authors, and leaders of environmental organizations. In order to cover all of the important information from these public figureheads, tweets from 100 users were collected using the Twitter API. The Python library tweepy provides a user-friendly application to extract large amounts of tweets in minimal time. These sets of tweets between 1000 and 3000 per user were then loaded to MongoDB with each user and his or her list of tweets as documents. This resulted in a total of 100 documents within the database.
By using natural language processing tools, such as NLTK and spaCy, it is possible to extract meaningful information from the tweets. Topic modeling can be used to find the most important set of words that define each user. The users can then be clustered based on the topics that represent their tweets the most. These clusters can help one navigate the through topics that are most important to the influencers, and thus, crucial to the environmental mission of sustainable action.
Preprocessing:
The following is an example of a raw tweet collected from the Twitter API. The formatting and special characters within the tweets naturally bring noisy data that makes the raw form difficult to interpret and analyze. Natural language processing is most effective when the texts are in the most basic and lemmatized form.

The bulk of the text preprocessing was done using regular expressions. This cleaned up the URL links, special characters, emojis, and HTML entities. spaCy was first used to eliminate the stop words, which occur in an overwhelmingly large proportion of English sentences. Lemmatization was then applied to eliminate the inflectional endings and return the dictionary form of words so that different forms of the same word are represented similarly. For example, “seeing” should not be distinguished from “see” because the two words both share the same meaning. Fully preprocessed tweets, such as the one below, are then used to build matrices and models.

Vectorization:
Tweets for each user were vectorized using two different techniques: count vectorizer and term frequency - inverse document frequency (TF-IDF). Count vectorizer returns a sparse matrix of the term frequency for every word in the document. TF-IDF also accounts for the term frequency, but diminishes the weight of terms that occur in every set of document. This creates a matrix that emphasizes the unique terms in each document, which is more representative of important words to the document. Each column represents words in all the document and each row represents a user and their weighted score for each word. TF-IDF returned better results from this dataset since it eliminated common words like “the” and “this”, which appeared in a majority of tweets. N-grams of 1 and 2 were selected in order to account for the different meaning the same words may have in different contexts.
Topic Modeling:
Topic modeling and dimensionality reduction were then applied to the sparse matrix generated from TF-IDF vectorizer. By reducing the dimensions of the matrix, a simpler and more generalized model can be used to explain the documents. Fewer topics give more interpretability to understand the topics that are most important to each user. Three different types of dimensionality reduction techniques were attempted: LSA, NMF, and LDA. LSA, which uses SVD for matrix decomposition on words in documents, returned the most interpretable results. The number of components were reduced from 100 to 30, but still explained over 90% of the variance. The insignificant sacrifice made for a simpler and more interpretable model was worth the fraction of explained variance ratio lost.
Clustering:
Based on the features or topics that were generated from matrix decomposition, users could be clustered into similar groups. Three different clustering techniques were applied to the reduced matrix: K-Means, agglomerative, and DBSCAN. Although K-Means and agglomerative both returned interpretable results, K-Means performed better because of better distributed clusters.
When choosing the number of clusters for K-Means, it is important to lower inertia in order to regularize and generalize the model. However, the silhouette score must also be maximized for stronger relations of users within clusters. Based on the plots below, 5 clusters was a reasonable compromise, given how much easier it is to label 5 clusters versus 17 clusters.
The clusters were visualized on a 3D plot generated from Plotly. In order fit the plot in three-dimensions, the dimensions had to be further reduced using LSA. Each axis represented a set of words to make up a topic. The 3D plot show clear and distinct clusters with even distribution of users in each cluster. The interactive plot also show details of each user when the mouse is hovered over each point.
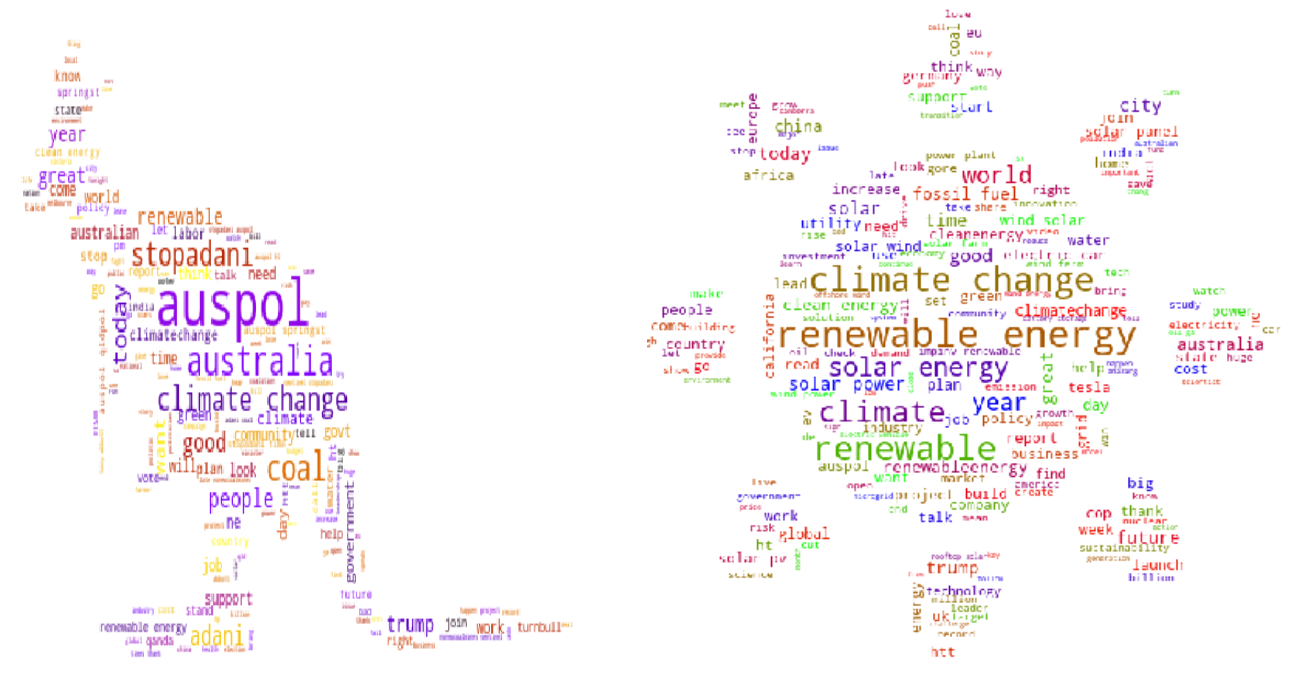
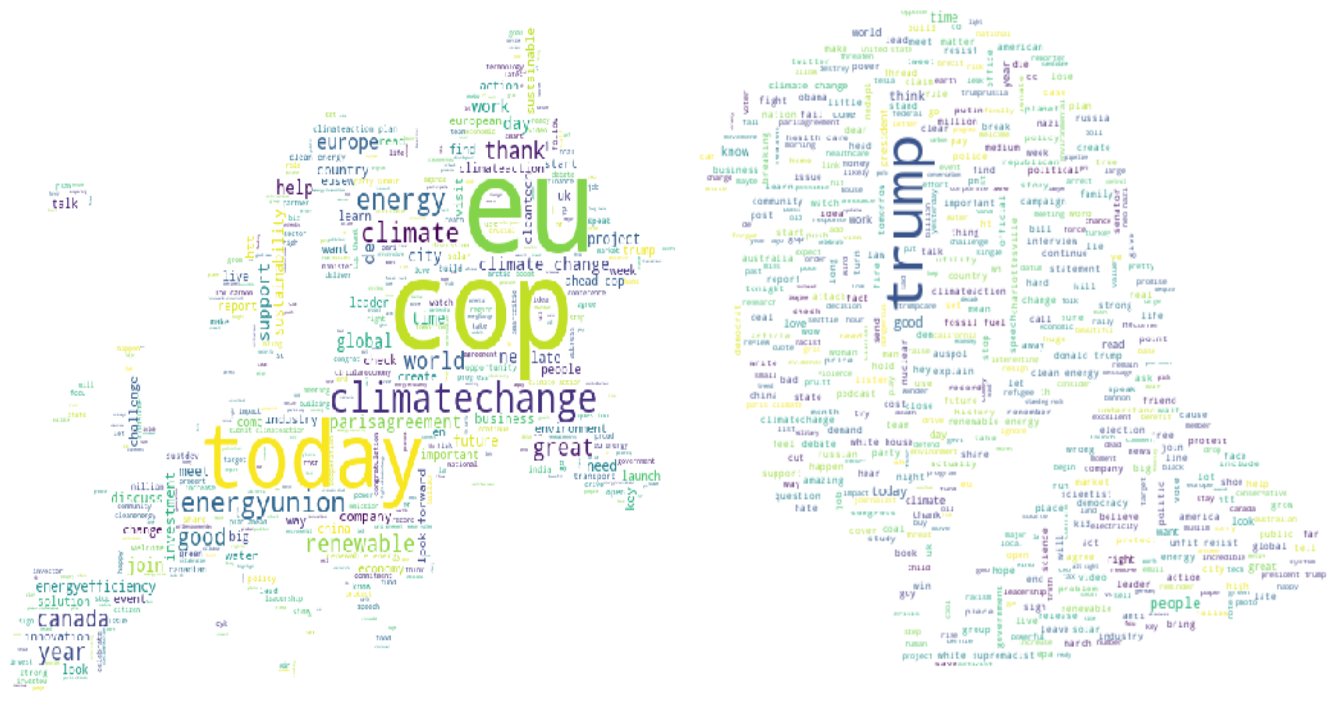
Word clouds were also generated to visualize the clusters in more detail. This Python package accepts texts in the cluster, and calculates the term frequency of the most popular words. Words with higher term frequencies are returned in larger font, indicating the importance of the word to the cluster.
The first cluster generated a word cloud that brought up words regarding Australia and coal. Adani is the investment group behind Australia’s most controversial coal project. The proposed Carmichael coal mine is expected to be the largest coal mine in Australia and one of the largest in the world. In an age where it is crucial to reduce low-quality coal generation, it makes sense that this project is a high priority list of concern for clean energy leaders.
The second cluster shows many words regarding renewable energy and specific technology that are highly sought in progressive environments. It is evident that users in this clusters care more about proposing solutions to drive the world into the next generation of energy technology.
The third cluster have several words that stand out distinctly from the rest: “EU” and “COP”. These terms refer to the Conference of Parties in the European Union that assesses progress dealing with climate change. The next COP23 is held in Bonn, Germany, so it is a major subject of conversation in the European region.
The main word that stands out in the fourth cluster is “Trump”. There are other words, like “GOP” and “Charlottesville” that are closely related to Donald Trump with the recent white supremacist rally. It is safe to assume that this group of users are involved with national politics, and have their eyes focused on detrimental actions that the US government might take on climate change or other key areas of social justice.
The final cluster is a little more difficult to interpret based on the larger words in the word cloud. However, the distinct words that appear only in this cluster are “UK”, “Brexit”, and “Nuclear”. The TF-IDF results on this cluster show that these three words are the most defining words of the cluster. This cluster of users appear to be concerned with the British inclination to bring back nuclear power as a major source of energy.

Sentiment Analysis:
With 5 clearly defined clusters, it is still important to verify the clusters’ stance on each major topic. While there is a tendency to assume that clean energy influencers will usually stand for the most progressive energy technologies and policies, this field is complicated and may not always present expected results. Vader Sentiment Analyzer is a method in NLTK that can generate the proportion of positive, negative, and neutral sentiments in a given sentence.
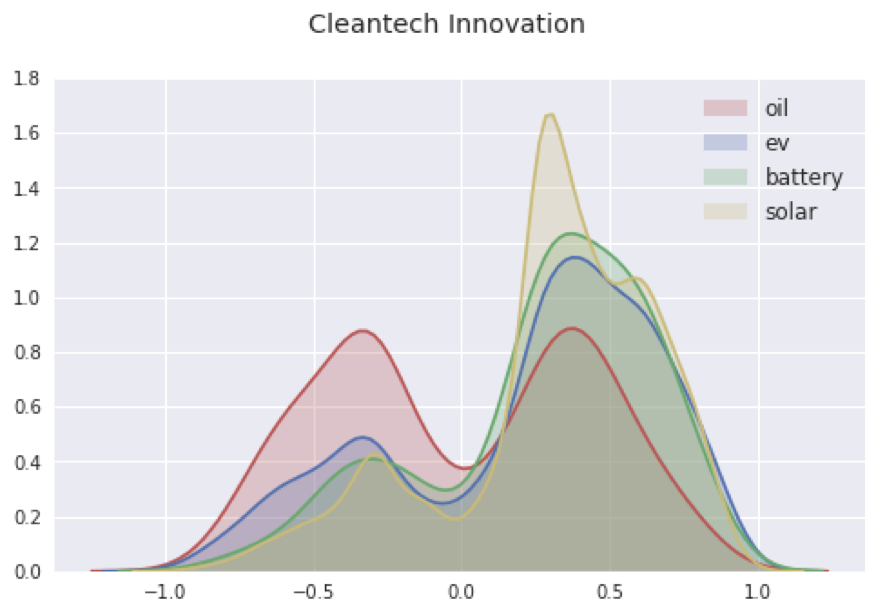
In the Kernel density estimation plot for the “Cleantech Innovation” cluster, it is evident that a large amount of positive sentiments were associated with clean energy technology, such as solar energy, batteries, and electric vehicles. Although oil has more positive sentiments than expected, the negative sentiments are significantly higher than the renewable technologies. The distribution of sentiments for this cluster was, for the most part, as expected from a progressive group of people.
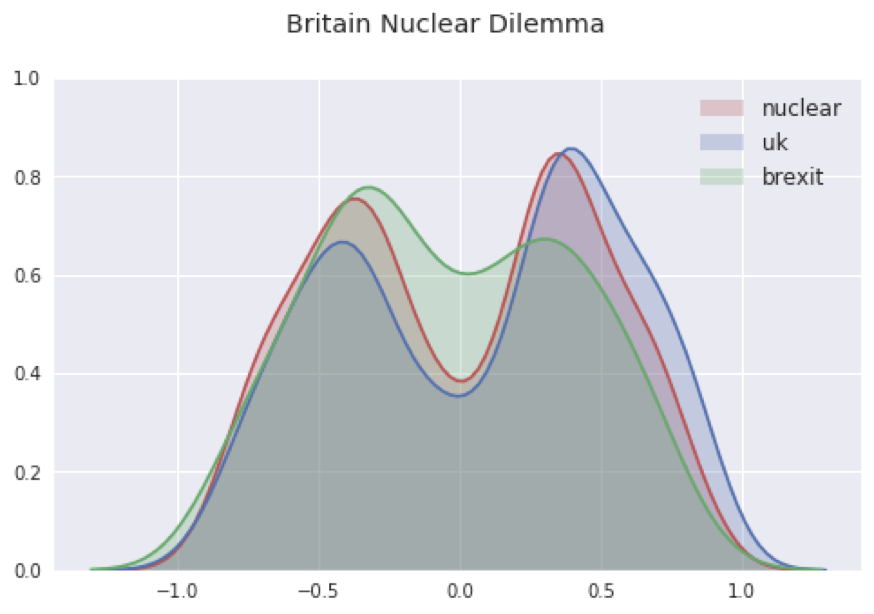
Another example with the “British Nuclear Dilemma” cluster shows mixed results. While there were many negative sentiments with “Brexit”, “Nuclear” received more positive sentiments that negative. The overall distribution shows that there are sizable amounts of positive and negative sentiments for every topic. Sentiment analysis in this case was more inconclusive and needed further evaluation.
The following are two example tweets extracted from users in the cluster mentioning “nuclear”. The first tweet admits that renewable is the better option, but nuclear is still a significant improvement over coal, especially for a developing country like India. It is understandable that this user may be a clean energy advocate, but still applauds any type of progress. The second tweet shows that the user clearly opposes nuclear technology in the UK. However, the tweet structured in a way that makes it difficult for Vader Sentiment Analyzer to pick up the sarcasm. This is an example of shortcomings with sentiment analysis despite representing most topics accurately.


Next Steps:
Natural language processing techniques allowed the creation of 5 easily interpretable and distinct clusters from 100 clean energy influencers on Twitter. The most frequent words in each cluster showed the topics that the influencers cared about the most. Sentiment analysis on the top subjects in the clusters were mostly in line with what is expected out of progressive agendas, but showed some inconsistencies for certain topics. Further text cleaning can improve the accuracy of sentiments. Additional features in a more finely tuned sentiment analyzer can provide even more accurate results.
Overall, the results has proven the potential of social media to help the general population follow important developments in solving the most challenging problem of our lifetime. Clustering of major influencers in clean energy and environmental policy allows a more convenient and streamlined method to follow news, so people can turn directly to the experts for guidance on what actions to take in order to fight climate change and drive positive change to keep a safer and more sustainable world.