Music Genre Classification

Background:
Scientific research has proven that music can improve health of listeners in various ways. Some of these benefits include better sleep, lower stress, elevated mood, and strengthened learning capabilities. Music has existed for many millenia and can be found in almost any culture. Many different music genres have been born in the past few century and share some common characteristics with others. The adoption of different elements is what helped modern music become what it is today.
Music streaming companies’ business model is based on the number of listeners on their platform. The profit is generated through either monthly subscriptions or advertising money. In order to keep listeners engaged with their services, it is crucial to recommend new music that share similar traits to their listening patterns. Introducing listeners to new genres can potentially open doors to a larger library, which mutually benefit the music streaming companies’ business and listeners’ satisfaction.
Data:
The Free Music Archive (FMA) was launched in 2009 as an interactive library of high-quality, legal audio downloads directed by WFMU, the most renowned freeform radio station in America. Their goal is promote free access to all types of genres of music with a library of over 10,000 tracks.
Echo Nest API is used to analyze these individual tracks, returning over 200 different audio features generated by the software. For the purposes of this project, the number of audio features used to build the model was limited to 11: acousticness, danceability, energy, instrumentalness, liveness, speechiness, tempo, valence, artist familiarity, artist discovery, artist hotness. Multiclass classification models were built in order to accurately predict the genre. The number of targets or genre were limited to the top 10 most popular labels.
Analysis:
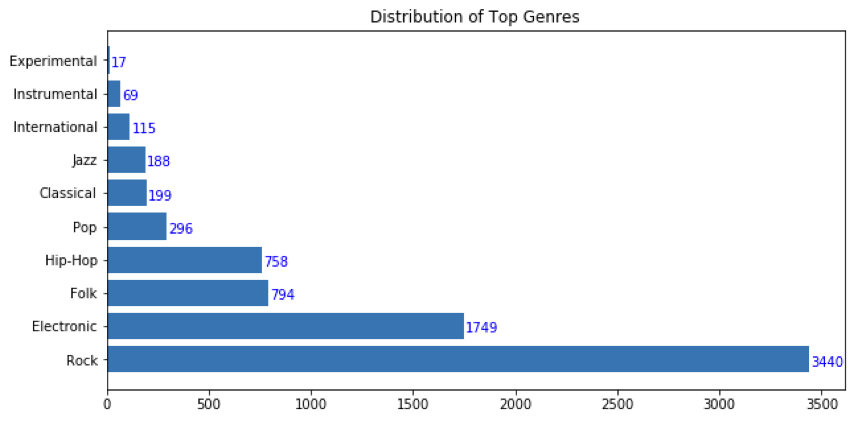
Initial cleaning of the data cut the number of tracks to just under 8000 by eliminating tracks that did not have a clearly defined top genre. The distribution of the genres below show that rock is by far the most common genre in this library, followed by electronic. Assuming that all track predictions are rock music, the baseline accuracy or dummy classifier has a score of 0.451.
Machine Learning Models
The following machine learning models were built to classify the target using supervised learning techniques: K-Nearest Neighbors, Logistic Regression, Random Forest. GridSearchCV from the sklearn library was applied to each model to find the parameters that returned the highest accuracy score.
The K-Nearest Neighbors model returned an accuracy score of 0.5255 using K of 15 neighbors. The model was built starting with a K of 2 neighbors, which was overfitted and did not perform well with cross validation. The accuracy score kept improving until 15 neighbors when the model began underfitting with larger K-values.
The Logistic Regression model was fitted using multinomial parameter instead of one-vs-rest, where a binary problem would be fit for each label. Consequently, limited-memory BFGS was the algorithm used to handle multinomial loss and handle L2 penalty.The C parameter, which represents the inverse of regularization, was also tuned to 0.6552 to prevent overfitting. The accuracy of the model slightly improved over the K-Nearest Neighbors model with a score of 0.5763.
The Random Forest Classifier model returned the highest score of 0.746. Trees with max features of 2 best prevented overfitting with the model. The criterion generally does not affect the model significantly, but entropy was used in this case to split the trees by the measurement of information.
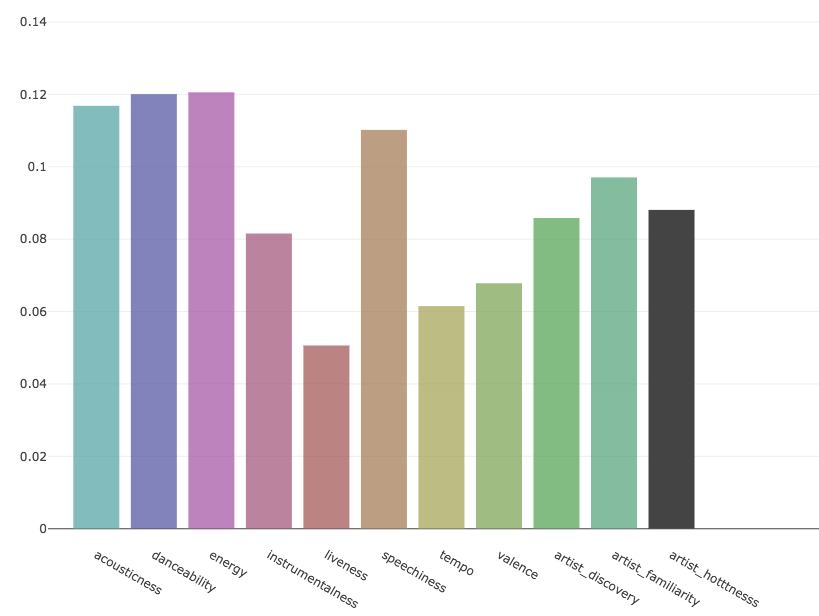
The feature importances of the Random Forest model plotted out on the bar chart below show a uniformly distribution. The implication here is that all the features were important to the high performance of the model. This is generally true of most Random Forest models, where the accuracy improves with more data.
Genre Similarity
Similar genres can be determined by observing the probability of each genre for each track. The genre with the second highest probability for each genre is listed as the pair. These genre pairs can show the overall relationship and similarity between the genres. Bar charts for each target were plotted to show the most similar genres based on the pairs. Since there were significantly more rock and electronic tracks, the percentages of the total number of songs specified as that top genre were plotted instead of the raw numbers. These plots were created with Bokeh to include interactive tab panes that gives a more condensed layout to visualize the genre similarities.
Rock music shows similarities with most other genres, which could be due to the large proportion of rock music in the dataset. Electronic music also shared strong similarities with many other genres, such as experimental and hip-hop. Aside from the two most popular genres, the most interesting finding was classical music similarity with folk and jazz music.
Genre similarity was also visualized with an interactive chord diagram built using Plotly. This visualization technique is especially useful to observe relationships within a dataset. The ideograms around the circumference proportionally illustrate the total number of tracks that fit the genre with the arc lengths. The ribbons in the middle that connect two nodes describe the relationship between the two genres with the number of tracks with the genre pairs. The chord diagram helps visualize the genre pairs all on one figure, which is useful to get an overall perspective of genre similarity.
Application
A simple interactive application to predict genre based on musical features was built using Flask. Each feature has a range input that can be dragged to a specified value, which will then output the number for better accuracy. After submitting the features with the click of the button at the bottom, the app will return the genre of music that had been inputted.
Next Steps:
The Random Forest model returned a much higher accuracy score than the K-Nearest Neighbors and Logistic Regression models. The accuracy score of 0.746 showed over a 50% improvement over the baseline model. This model’s predicted probability of each genre indicated the presence of rock and electronic music elements in most other genres. The large number of tracks for these two genres likely contributed this. Setting these two genres aside, the similarity of classical music to folk and jazz was perhaps the most interesting finding. Knowledge of genre similarity can potentially connect listeners to explore new genres of music, which can boost the listeners’ overall wellbeing and significantly increase revenue for the music streaming industry.
In the future, more audio features from the Echo Nest API can be used to improve the accuracy of the model. The current model excludes the over 200 temporal features for the sake of simplicity. More data for genres other than rock and electronic music can be mined as well in order to create a more balanced dataset. These changes can help the model predict the genre and second most probable genre more accurately, which can then more successfully recommended new music that listeners will like.